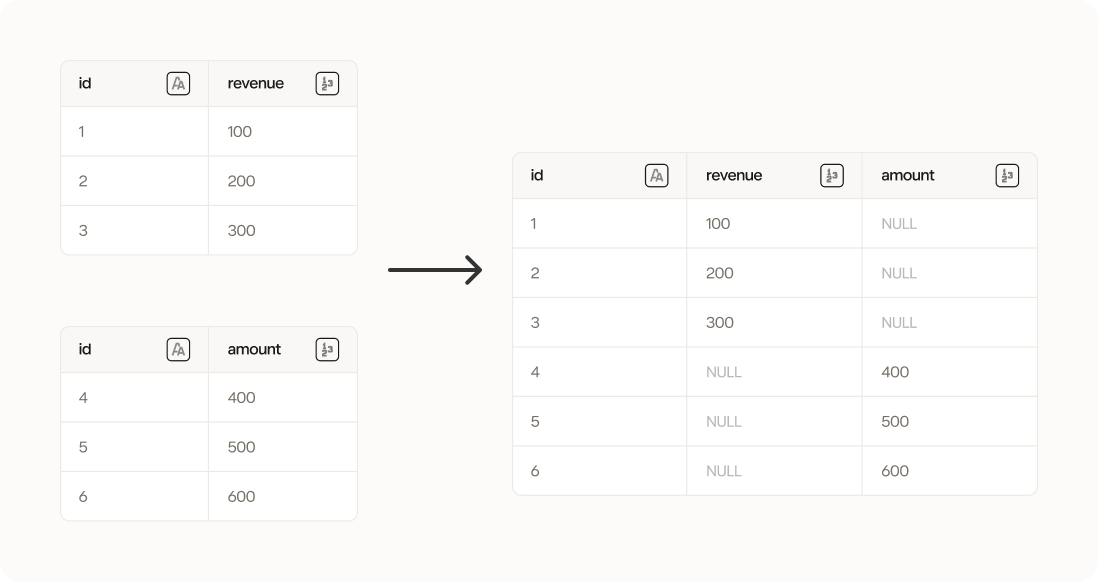
Configuration
You have two optional configuration steps:Dataset column matching
By enabling this option you place a restriction that all tables that are stacked must have exactly the same columns. If one of the tables doesn’t, then the Stack tool will fail. This is helpful if you know that all tables should match 1:1 in their structure.