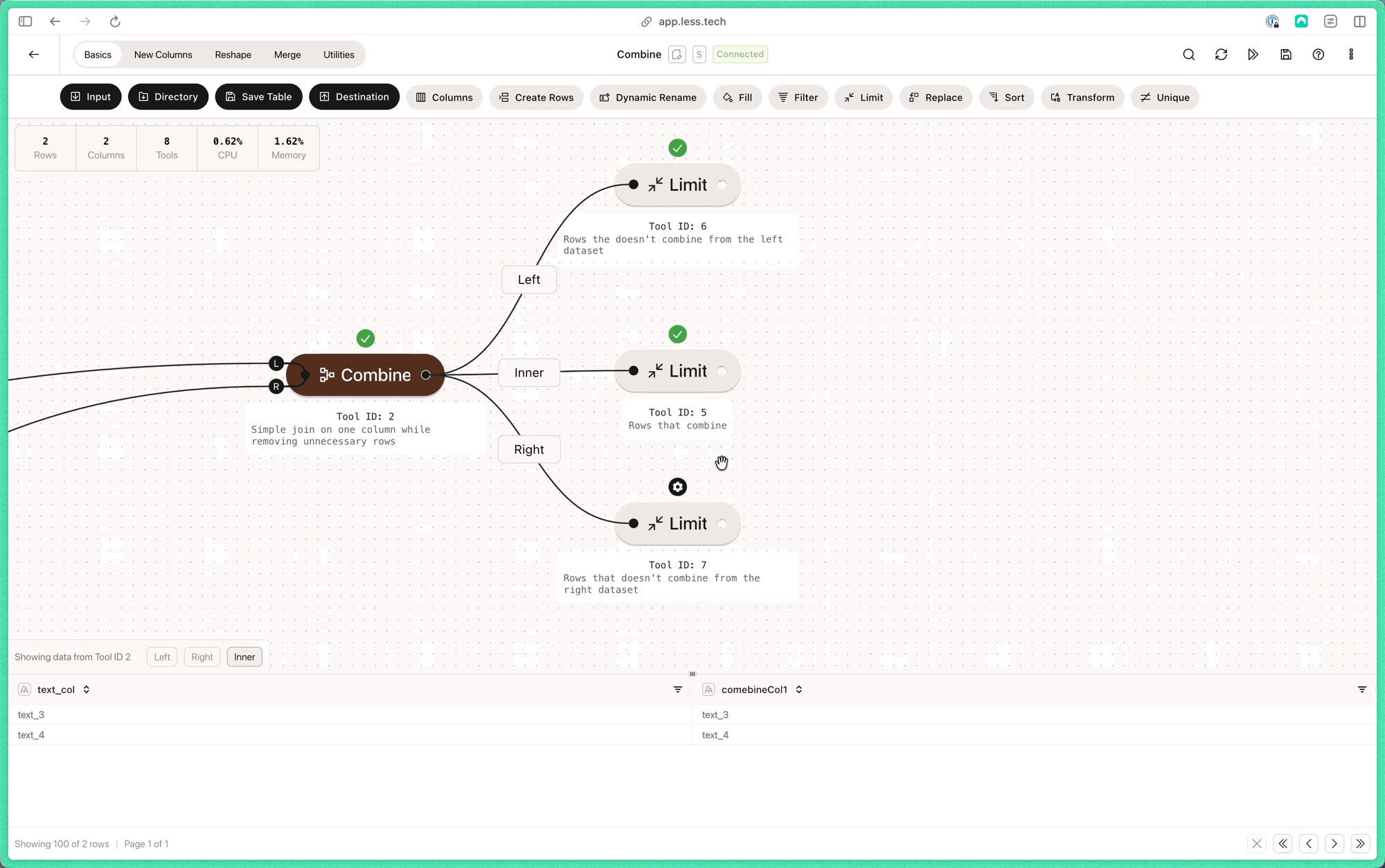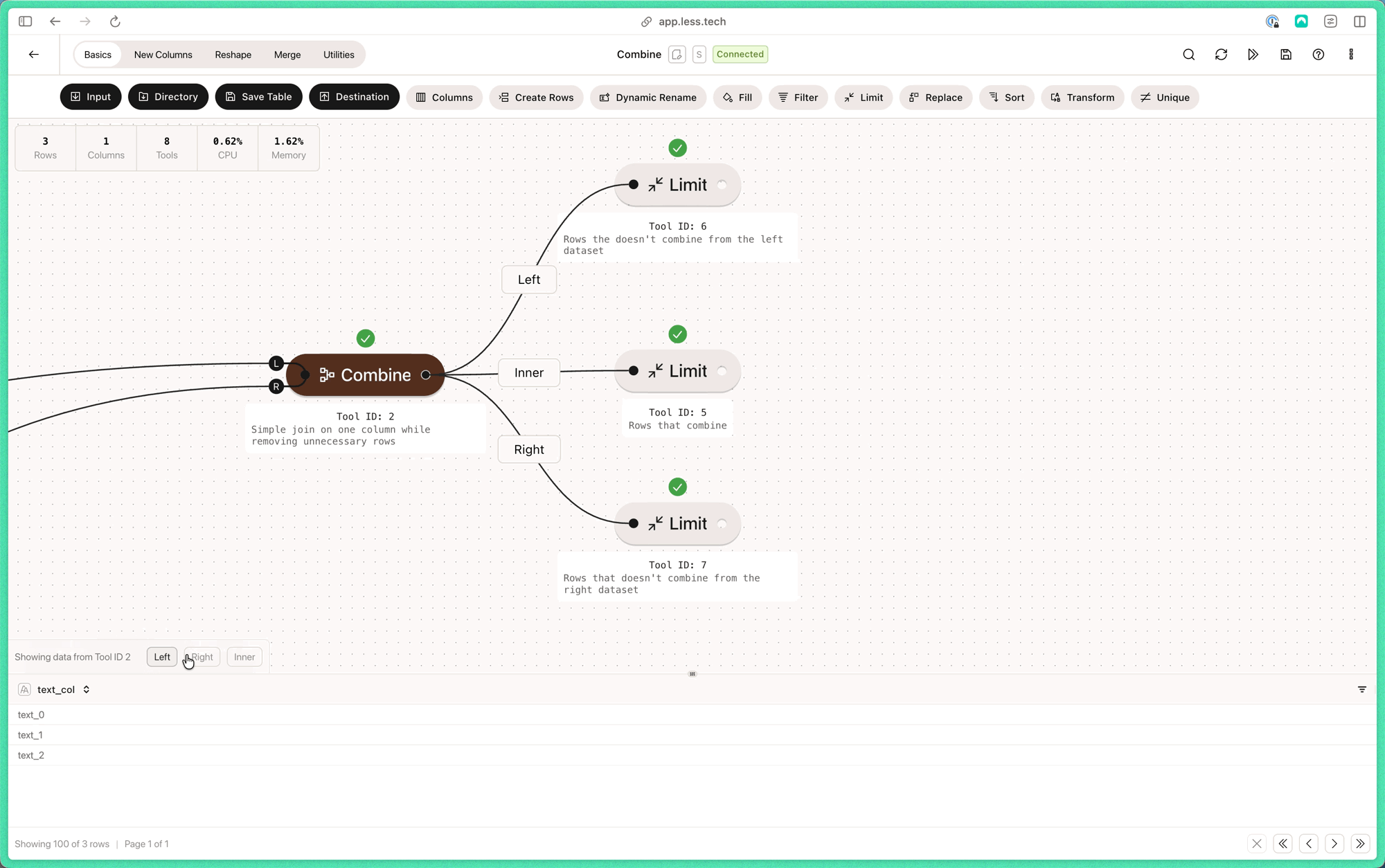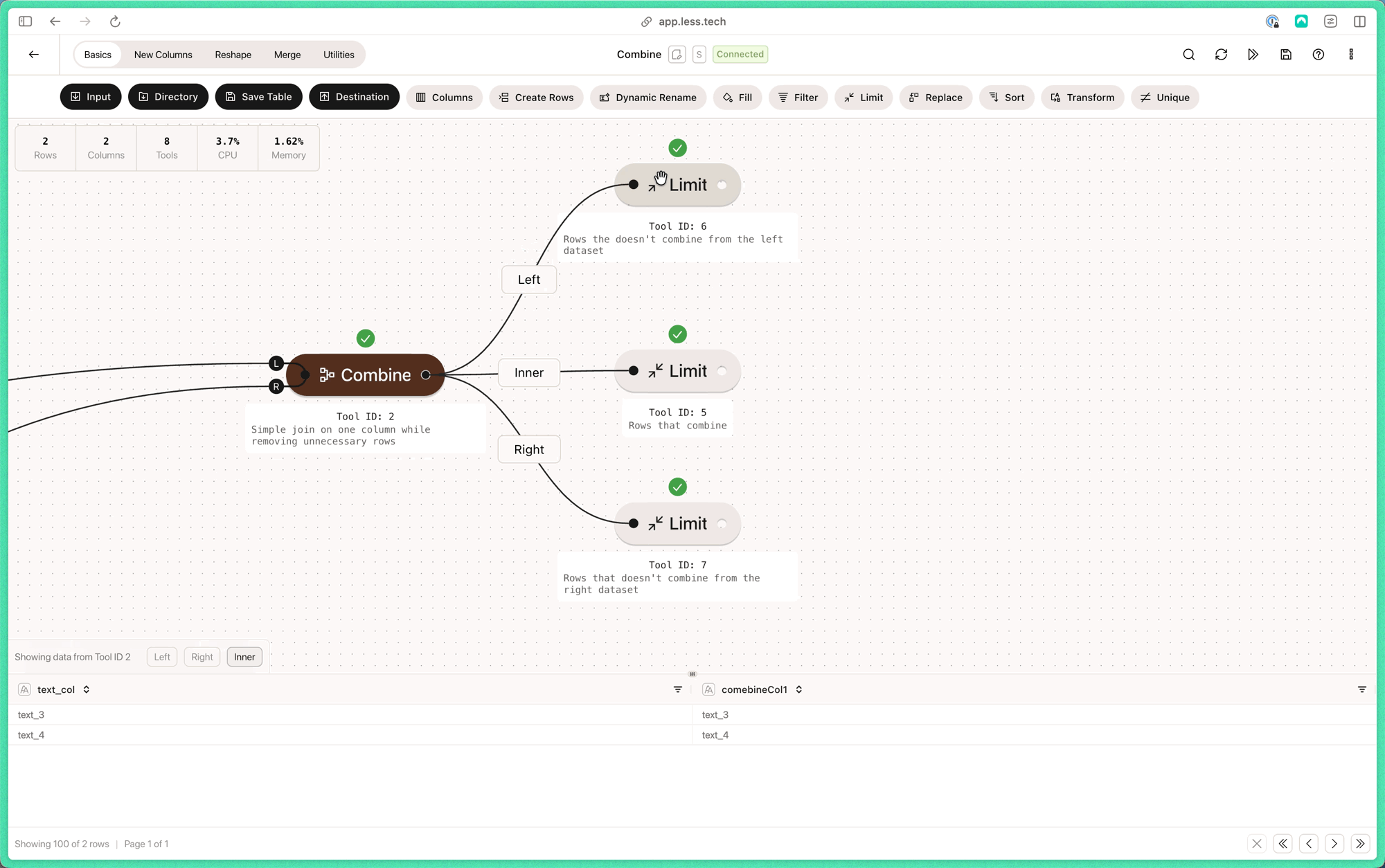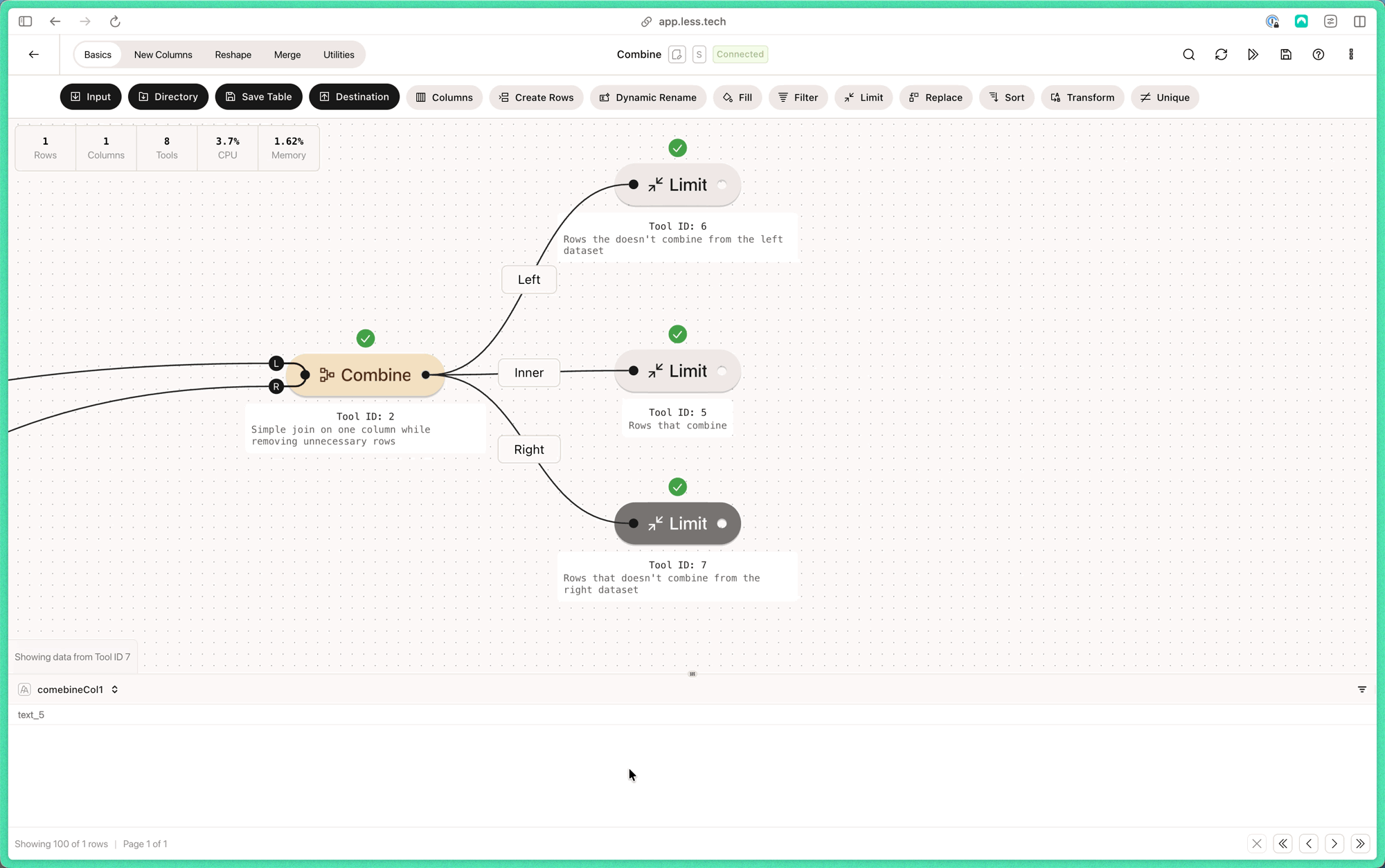
Configuration
Note that the L and R of the Combine anchors refers to left table and right table respectively.1
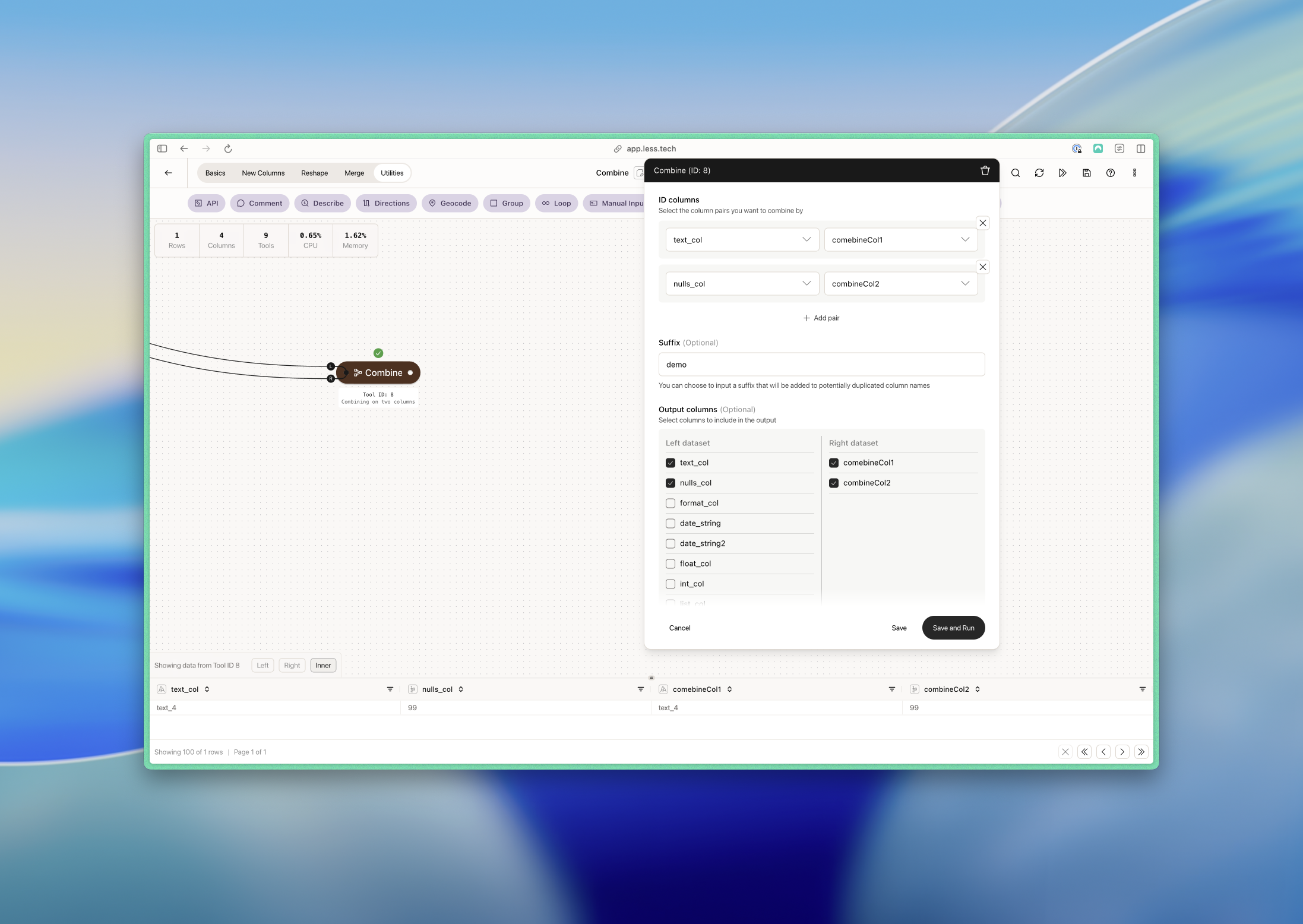
ID columns
Choose which columns to use as ID columns. The right column refers to the R anchor and the left column refers to the L anchor.You can add as many ID columnn pars as you need with the ”+ Add pair”-button. Check out the examples below.
The ID columns must be the same data type.
2
Suffix (optional)
You can choose to add a suffix to the output columns. This is useful if you potentially have duplicate columns in your datasets.
3
Output columns (optional)
You can choose to select the output columns in dataset. This is like a built-in Columns tool (though slightlty less sophiscated).
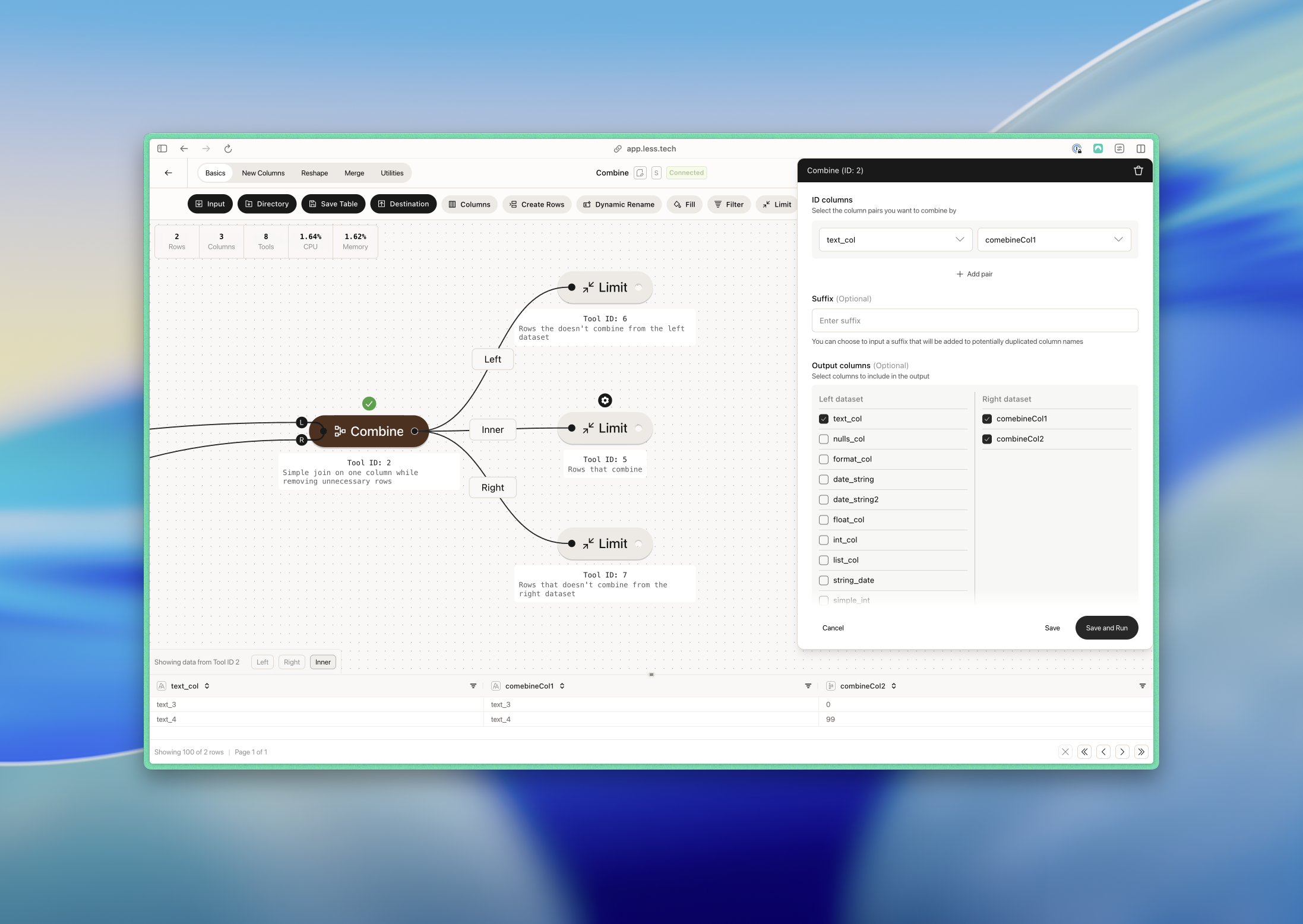
Example: Single ID column
Here we have a simple example where we want to combine on text_col (L) and combineCol1 (R). We deselect a lot of columns from the left dataset while we’re at it.- Left dataset
- Right dataset
- Output


Example: Multiple ID columns
Here we combine with two column pairs. Notice how - as opposed to the example above - we only match a single row because this row matches both of our column pairs.- Left dataset
- Right dataset
- Output